¶ Qu'est ce qu'hydra?
hydra est une plateforme de modélisation hydrologique et hydraulique permettant :
- De faire appel dans un même modèle aux fonctionnalités propres aux réseaux d’assainissement, aux systèmes fluviaux et maritimes afin de répondre aux problématiques complexes d’interconnexion des réseaux de collecte des eaux pluviales et des débordements de surface dans la gestion des inondations des grandes métropoles,
- De disposer de fonctionnalités ergonomiques, fluides et intuitives pour la construction et l’exploitation des modèles,
- D’être totalement compatible avec les standards du monde SIG, aussi bien en entrée (construction des modèles) qu’en sortie (exploitation des résultats),
- De s’intégrer dans un environnement logiciel libre afin d’offrir la possibilité aux utilisateurs de développer des applications métier spécifiques autour cette plateforme.
Les périmètres concernés couvrent une gamme géographique très étendue selon les natures des phénomènes modélisés : quelques dizaine de mètres pour les études hydrauliques locales à plusieurs centaines de km² pour les études globales et intégrées de grands systèmes hydrographiques.
Cette plateforme permet de piloter un moteur de calcul robuste et performant, fruit de 30 ans de développement et d'exploitation, capable de traiter l’ensemble des domaines suivants ainsi que leurs interactions :
- hydrologie : calculs des lames d’eau précipitées temps réel et prévisions pluviométriques par exploitation d’images radars, modélisation des ruissellements de surface et dans les branches amont de réseaux de collecte,
- modélisation des écoulements et des propagations de crue dans les réseaux d’assainissement, les cours d’eau et les plaines inondables,
- modélisation des interactions entre les débordements de cours d’eau, les débordements de réseaux d’assainissement et les écoulements de surface dans les zones urbaines,
- modélisation des échanges nappes-rivière, des remontées de nappe et des conséquences sur les débordements de surface (en cours de développement).
- modélisation des submersions marines, intégrant les effets de marées, de surcotes, de vents et les franchissements d’ouvrages par la houle,
- modélisation des phénomènes transitoires rapides et leurs conséquences : rupture de barrage, fermeture rapide de vannes dans les canaux et formation d’intumescences, formation de mascarets dans les régions estuariennes …
- modélisation courantologique dans les cours d’eau, les estuaires et régions côtières, simulation des impacts de rejets polluants sur la qualité du milieu récepteur : cours d’eau, estuaires, régions côtières,
- modélisation du transport solide et analyse d’impact des aménagements sur le transport hydro sédimentaire et ses conséquences sur les phénomènes d’incision et d’ensablement dans les cours d’eau.
- Analyse locale fine d’ouvrages hydrauliques tels que : seuils déversant, chenaux de décharge, vannages …
- optimisation de gestion des ouvrages et des grands systèmes hydrologiques et hydrauliques.
L’interface se présente sous forme d’un plugin de QGIS, SIG (système d’information géographique) libre, multi plateforme, publié sous licence GPL, dialoguant avec une base de données PostgreSQL. Les objets de modélisation sont décrits et stockés dans cette base de données, et affichés dans QGIS sous forme de couches.
QGIS dans ce contexte est utilisé comme pré et post-processeur graphique, l’ensemble de ses fonctions restant accessibles à l’utilisateur.
Des outils spécifiques permettent de créer ces objets et d’éditer leurs caractéristiques.
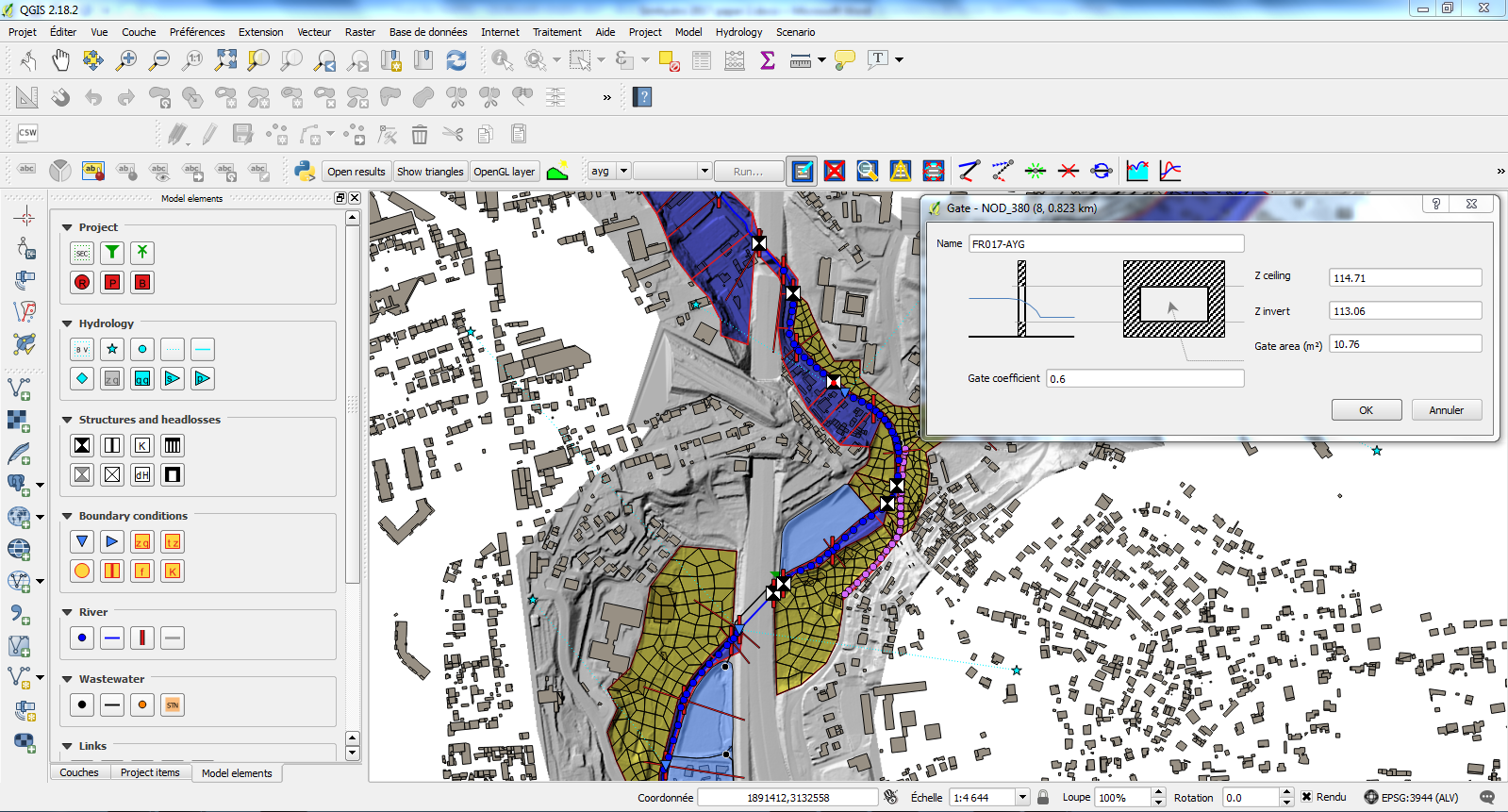
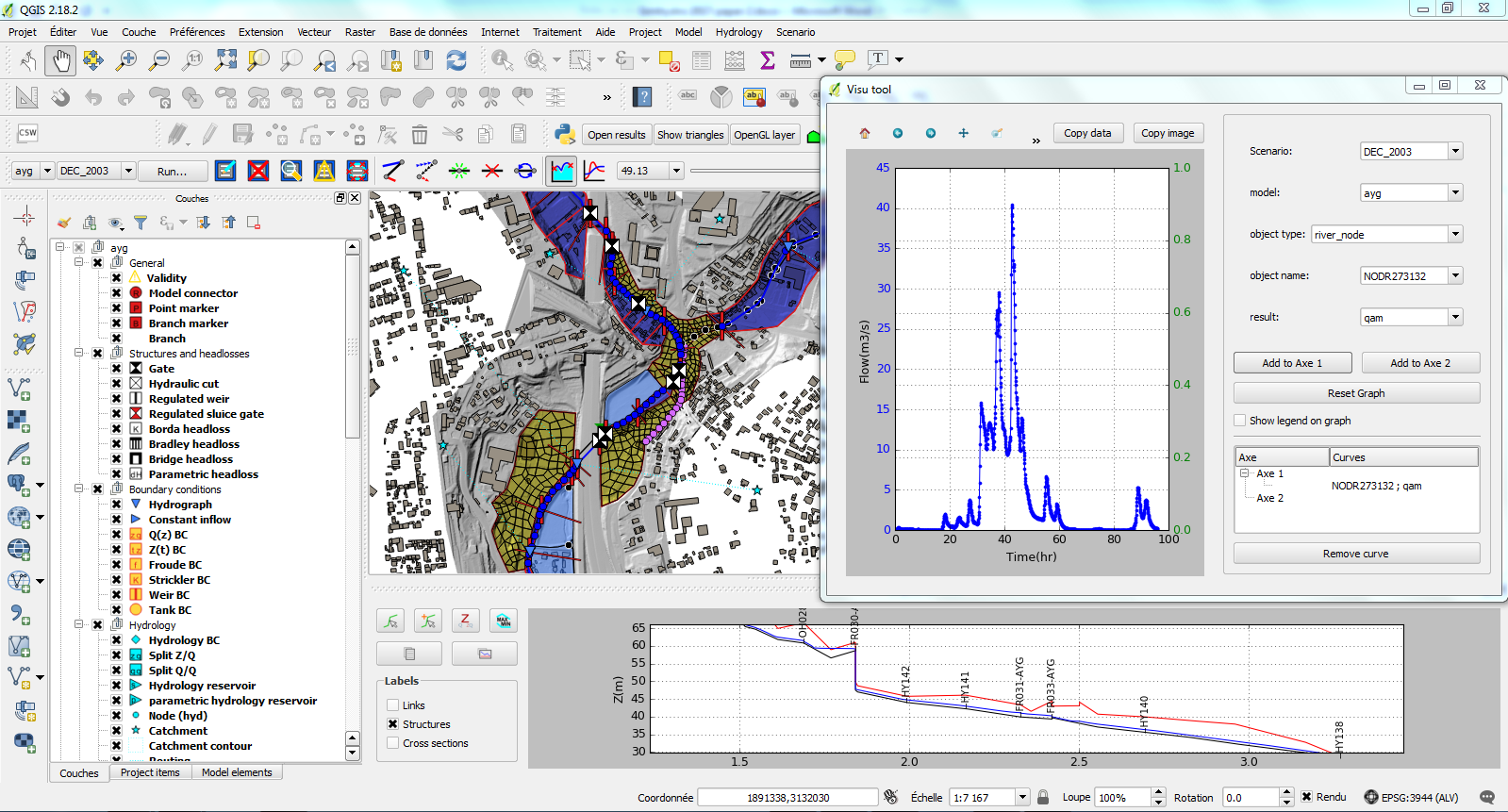
L’interface permet de paramétrer les scénarios de calcul, de lancer les calculs et d’effectuer les traitements des résultats : profils en long de lignes d’eau et de débits, hydrogrammes / limnigrammes sur les nœuds de calcul, cartographie des hauteurs d’eau et des vitesses d’écoulement, points de débordement des réseaux, …
¶ Architecture et environnement de développement
L’application regroupe deux parties totalement distinctes :
- L’interface utilisateur,
- Le moteur de calcul numérique.
¶ L'interface utilisateur
L’application est développée dans l’environnement QGIS, logiciel SIG (système d’information géographique) libre, multi plateforme.
L’architecture des modèles ainsi que l’ensemble des paramètres de calcul et données d’entrée et de sortie sont stockés dans une base de donnée PostgreSQL et son extension spatiale PostGIS (également open source) dialoguant directement avec QGIS. Ces données sont stockées dans des tables interconnectées selon un schéma conceptuel strict qui garantit la robustesse de l’application, facilite son évolution et les couplages vers des bases de données d’applications liées.
Les capacité de la base de donnée (PostgreSQL) ont été utilisées au maximum pour intégrer l'intelligence métier au plus près des données. Grâce à des vues couplées à des trigger instead-off, la base présente une véritable API (base de donnée épaisse): le maillage, le calcul ou la lecture des résultats sont de fonctions ajoutées à la base.
Cette approche permet de minimiser les aller-retour entre le code métier et la base de données et de garantir la parfaite intégrité des transactions. L’intégration dans la base de données des contrôles d’intégrité des données saisies permet également de gérer la qualité des données saisies le plus en amont possible.
Cette structuration permet de mieux capitaliser l'intelligence métier, de garantir l'intégrité des données en entrée du code de calcul, et ouvre la porte à d'autre clients que QGIS pour interagir avec le modèle.
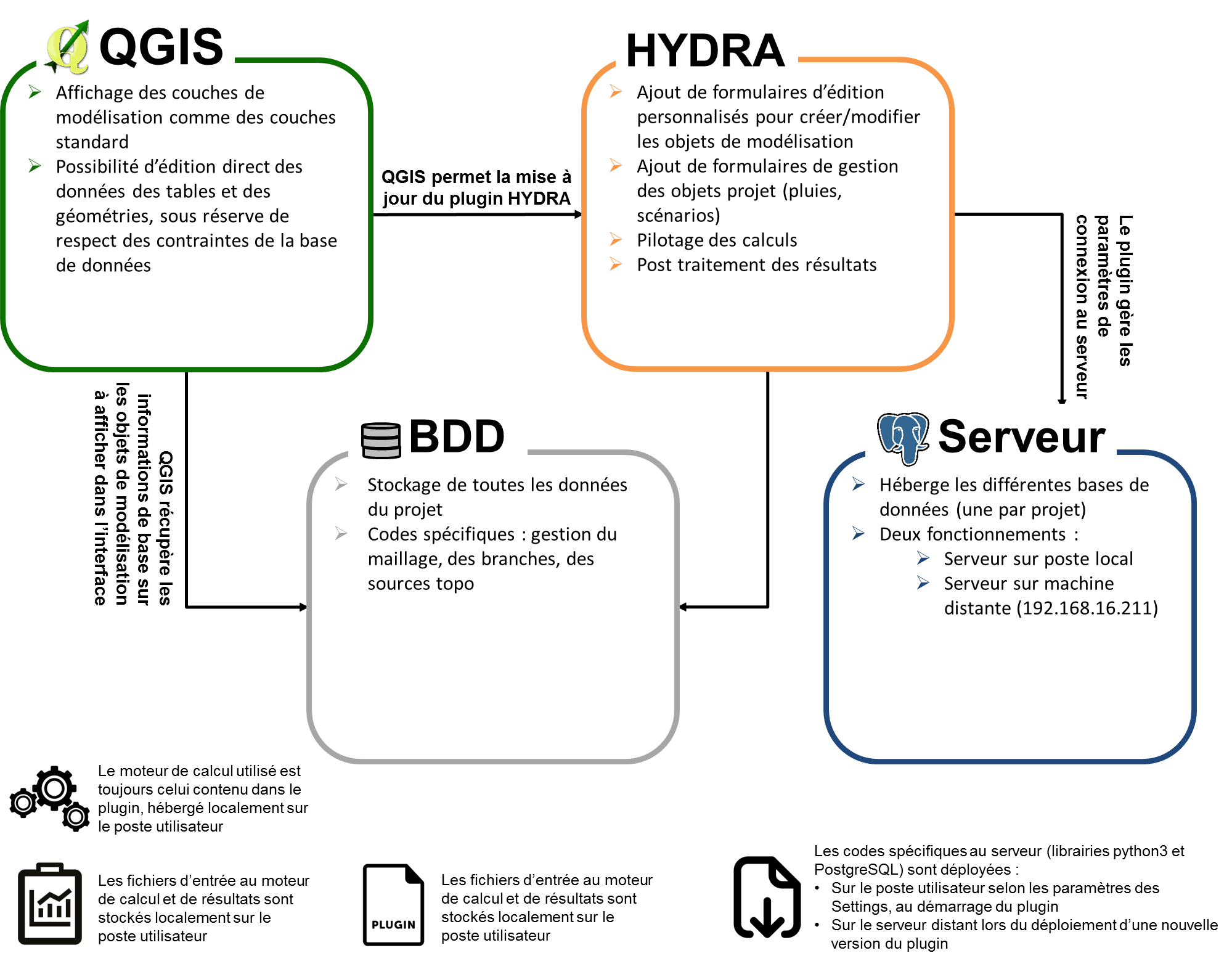
Le plug-in regroupe un ensemble de fichiers scripts en langages Python et SQL, installés sur l’ordinateur client.
La base de données peut être implantée sur un serveur distant et accessible via une architecture client-serveur, ou localement sur le poste utilisateur accueillant le plug-in.
¶ Le moteur de calcul
Le moteur de calcul est totalement indépendant de l’interface et de l’application QGIS. Il est développé en langages compilés C et Fortran et se compose de fichiers exécutables au format binaire .exe.
Une simulation est lancée via le plug-in de l'interface, qui génère des fichiers d’exports des données tabulaires de la base de données sous-jacente et lance les exécutables en séquence.
Après calcul, les exécutables produisent des fichiers résultats au format binaire et CSV qui sont exploités par les différents outils d’exploitation du plug-in ou des programmes externes spécifiques.
La formulation sous-jacente du moteur de calcul hydra est fondée sur le concept de discrétisation des équations en volumes finis avec fondamentalement deux familles de termes :
- les termes de volumes et d’inertie attachés aux nœuds de calcul élargis aux objets de stockage.
- Les termes d’échanges de flux ( débits, quantités de mouvements) entre les nœuds.
A chaque pas de temps les équations discrétisées expriment l’égalité entre les variations des termes de volumes et d’inertie et les flux rentrant et sortant dans chaque nœud.
Cette conceptualisation de la modélisation hydraulique est commune à tous les domaines physiques gérés par Hydra et constitue le socle sur lequel est fondé le Modèle Conceptuel de Données présenté au chapitre suivant.
¶ Intérêt et contraintes de cette organisation logicielle
Le caractère open source des différents composants de l’IHM les rend facilement accessibles et modifiables, et facilite les collaborations et synergies avec nos partenaires/clients actuels et futurs autour de cette nouvelle plateforme. L’application s’intègre ainsi naturellement dans un écosystème dynamique comportant des acteurs du monde de l’ingénierie de l’eau, des SIG, du numérique et d’internet.
Le moteur de calcul d’hydra reste un outil propriétaire, il échappe aux règles de contamination de la réglementation GPL, il se comporte comme un composant exploité en mode esclave, sans interférence directe avec l’utilisateur.
Les fonctionnalités du plugin sont quant à elles très générales et permettent d’envisager dans une phase ultérieure de piloter des moteurs de calculs autres qu’hydra, du moins ceux disponibles en open source.